各々の文字には、PCで利用する為に固有の識別番号が割り当てられており、これを文字コードと呼びます。
文字にはUnicode®の何番、Shift_JISの何番、JISの何番、というように国際規格や各国の規格により違うコード番号が割り当てられています。

フォントファイルは、複数の文字を集めた文字セット(文字集合)の形で提供されます。
文字セットには、「Microsoft CorporationのWindows® Codepage(CP)」、「ISO(国際標準化機構)規格」、「JIS(日本工業規格)」
「ARIB(一般社団法人 日本電波産業会)規格」、「GB(中国国家標準)」などいくつかの種類があり、文字セットによって、含まれる文字種(文字の種類)、文字数が異なります。
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP932 | JIS X 0201(半角) | 158 |
| JIS X 0208(非漢字) | 616 | |
| JIS X 0208 第1水準漢字 | 2,965 | |
| JIS X 0208 第2水準漢字 | 3,390 | |
| NEC特殊文字 | 89 | |
| IBM®拡張文字 | 374 | |
| NEC選定IBM®拡張文字 | 0 | |
| 合計 | 7,592 | |
| JIS X 0208-1990 | JIS X 0208(非漢字) | 577 |
| JIS X 0208 第1水準漢字 | 2,965 | |
| JIS X 0208 第2水準漢字 | 3,390 | |
| 合計 | 6,932 | |
| CP932+JIS X 0213:2004 | JIS X 0201(半角) | 158 |
| JIS X 0208(非漢字) | 616 | |
| JIS X 0208 第1水準漢字 | 2,965 | |
| JIS X 0208 第2水準漢字 | 3,390 | |
| NEC特殊文字 | 89 | |
| IBM®拡張文字 | 374 | |
| NEC選定IBM®拡張文字 | 0 | |
| JIS X 0213 非漢字 | 575 | |
| JIS X 0213 第3水準漢字 | 1,071 | |
| JIS X 0213 第4水準漢字 | 2,348 | |
| 合計 | 11,586 | |
| ARIB STD-B24 | JIS X 0201(半角) | 158 |
| JIS X 0208(非漢字) | 577 | |
| JIS X 0208 第1水準漢字 | 2,965 | |
| JIS X 0208 第2水準漢字 | 3,390 | |
| 追加記号 | 399 | |
| 追加漢字 | 137 | |
| 合計 | 7,626 |
ARIBおよびARIB対応フォントについて
ARIB(Association of Radio Industries and Businesses)とは、日本におけるデジタル放送や携帯電話に関する規格を制定している一般社団法人電波産業会という業界団体です。
デジタル放送では、ARIB規格に対応した文字の使用が求められています。
当社では、ハイビジョン放送まで対応した規格であるARIB STD-B24(デジタル放送におけるデータ放送符号化方式と伝送方式)に対応したフォントを提供しております。

中国本土などで使用されます。
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| GB18030-2005(強制部分) | 単字節 半角ASCII | 95 |
| 双字節1区 非漢字 | 728 | |
| 双字節5区 非漢字 | 166 | |
| 双字節2区 漢字 | 6,763 | |
| 双字節3区 漢字 | 6,080 | |
| 双字節4区 漢字 | 8,160 | |
| 四字節 漢字 | 6,530 | |
| 合計 | 28,522 |
GB(GB規格)
中国には、中国国家標準化管理委員会という団体によって承認・発表されているGB(GB規格)という国家規格が存在します。
国家規格を意味する「国家標準」を中国語読みした時の「Guójiā Biāozhǔn」という音声の頭文字を取ってそのように呼ばれています。
簡体字の認証
中国国内で利用される製品に簡体字を搭載する場合、ビットマップフォントについては中国政府が所有している標準フォント、アウトラインフォントについては中国政府の認証を取得したフォントが求められます。
当社では、情報処理製品標準適合性検査センター
(Conformance Test Center For Information Technology Standards:CTCITS)という中国政府公認の認証機関による適合性検査に合格しているアウトラインフォント(TrueType Font/RT Font)を提供しております。
中国政府所有の標準ビットマップフォントをお探しの方は無料相談にてお問合せください。
台湾などで使用されます。
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP950 | 半角英数 | 95 |
| Big5 非漢字 | 408 | |
| Big5 第1標準字集 | 5,399 | |
| Big5 第2標準字集 | 7,652 | |
| E-TEN | 7 | |
| 罫線素片 | 25 | |
| グラフィックパターン | 1 | |
| ユーロ記号 | 1 | |
| 合計 | 13,588 |
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| KS X 1001:2004(漢字を除く) + KS X 1003-1993 |
半角英数 | 95 |
| 字母 | 94 | |
| 記号 | 895 | |
| ハングル文字 | 2,350 | |
| 合計 | 3,434 |
| 地域/言語 | 文字セット | 文字数 |
|---|---|---|
| 西ヨーロッパ | ISO8859-1 | 191 |
| CP1252 | 218 | |
| 中央ヨーロッパ | ISO8859-2 | 191 |
| CP1250 | 218 | |
| 南ヨーロッパ | ISO8859-3 | 184 |
| 北ヨーロッパ | ISO8859-4 | 191 |
| キリル(ロシア語等) | ISO8859-5 | 191 |
| CP1251 | 223 | |
| ギリシャ語 | ISO8859-7 | 188 |
| CP1253 | 206 | |
| トルコ語 | ISO8859-9 | 191 |
| CP1254 | 216 | |
| 北ゲルマン語群 | ISO8859-10 | 191 |
| バルト語 | ISO8859-13 | 191 |
| CP1257 | 211 | |
| ケルト語 | ISO8859-14 | 191 |
【言語別文字セット対応状況】
| ISO8859 | CP | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 言語(日本語50音順) | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 13 | 14 | 15 | 16 | 1250 | 1251 | 1252 | 1253 | 1257 |
| アイスランド語 | ○ | ○ | ○ | ○ | ||||||||||||||||
| アイルランド・ゲール語 (旧正書法) |
○ | |||||||||||||||||||
| アイルランド・ゲール語 (新正書法) |
○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||||
| アイルランド語 | ○ | ○ | ○ | |||||||||||||||||
| アフリカーンス語 | ○ | ○ | ○ | |||||||||||||||||
| アラビア語 | ○ | |||||||||||||||||||
| アルバニア語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ||||||||||||
| イタリア語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||||
| インドネシア語 | ○ | ○ | ○ | |||||||||||||||||
| ウェールズ語 | ○ | |||||||||||||||||||
| ウクライナ語 | △ | △ | ||||||||||||||||||
| 英語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| エストニア語 | ○ | ○ | ○ | ○ | ○ | ○ | ||||||||||||||
| エスペラント語 | ○ | |||||||||||||||||||
| オランダ語 | △[1] | △[1] | △[1] | △[1] | ||||||||||||||||
| カタロニア語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| ガリシア語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| 北ゲルマン語群 | ○ | |||||||||||||||||||
| 現代ギリシア語 | ○ | ○ | ||||||||||||||||||
| グリーンランド語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||||
| クルド語 | ○ | |||||||||||||||||||
| クロアチア語 | ○ | ○ | ○ | |||||||||||||||||
| ゲール語 (マン島ゲール語) |
○ | |||||||||||||||||||
| コーンウォール語 (ケルト語) |
○ | ○ | ○ | ○ | ||||||||||||||||
| サーミ語 | ○ | ○ | ||||||||||||||||||
| スウェーデン語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||||
| スコットランド・ゲール語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| スペイン語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| スロバキア語 | ○ | ○ | ||||||||||||||||||
| スロベニア語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| スワヒリ語 | ○ | ○ | ○ | |||||||||||||||||
| セルビア語 | ○ | ○ | ||||||||||||||||||
| ソルビア語 | ○ | ○ | ||||||||||||||||||
| タイ語 | ○ | |||||||||||||||||||
| チェコ語 | ○ | ○ | ||||||||||||||||||
| デンマーク語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||||
| ドイツ語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||
| トルコ語 | △ | ○ | ||||||||||||||||||
| ノルウェー語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | |||||||||||
| ハンガリー語 | ○ | ○ | ○ | |||||||||||||||||
| バスク語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| バルト語派 | ○ | ○ | ||||||||||||||||||
| フィンランド語 | △ | ○ | △ | ○ | ○ | △ | ○ | ○ | ○ | ○ | ||||||||||
| フェロー語 | ○ | ○ | ○ | ○ | ||||||||||||||||
| フランス語 | △ | △ | △ | △ | ○ | ○ | ○ | |||||||||||||
| フリジア語 | ○ | ○ | ○ | ○ | ||||||||||||||||
| ブルガリア語 | ○ | ○ | ||||||||||||||||||
| ヘブライ語 | ○ | |||||||||||||||||||
| ベラルーシ語 | ○ | ○ | ||||||||||||||||||
| ブルトン語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| ポーランド語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| ボスニア語 | ○ | ○ | ||||||||||||||||||
| ポルトガル語 | ○ | ○ | ○ | ○ | ○ | ○ | ||||||||||||||
| マケドニア語 | ○ | ○ | ||||||||||||||||||
| マルタ語 | ○ | |||||||||||||||||||
| ユーロ記号「€(U+20AC)」 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| ラテン語 | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ | ○ |
| ラトビア語 | ○ | ○ | ○ | |||||||||||||||||
| リトアニア語 | ○ | ○ | ○ | ○ | ||||||||||||||||
| ルーマニア語 | △[2] | ○ | △[2] | |||||||||||||||||
| ルクセンブルグ語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| レト・ロマンス語 | ○ | ○ | ○ | ○ | ○ | |||||||||||||||
| ロシア語 | ○ | ○ | ||||||||||||||||||
【凡例】
○:対応しています。
△:ほぼ対応していますが、一部対応していない文字があります。
[1]:「IJ(U+0132)/ij(U+0133)」が欠けています。
[2]:「Ș(U+0218)/ș(U+0219)」と「Ț(U+021A)/ț(U+021B)」(コンマアクセント付きの文字)が欠けていますが、これらの文字はかつて「Ș(U+015E)/ș(U+015F)」と「Ț(U+0162)/ț(U+0163)」(セディーユ付きの文字)に統合されていました。
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP1256+137文字 | CP1256規定文字 | 223 |
| CP1256規定外の文字 | 137 | |
| 合計 | 360 |
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP1255+82文字 | CP1255規定文字 | 200 |
| CP1255規定外の文字 | 82 | |
| 合計 | 282 |
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP874 | CP874規定文字 | 192 |
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| CP1258+104文字 | CP1258規定文字 | 214 |
| CP1258規定外の文字 | 104 | |
| 合計 | 318 |
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| Unicode Devanagari 定義文字 | Unicode Devanagari 定義文字 | 155 |
OCR(Optical Character Recognition=光学文字認識)とは、手書きの文字や印刷された文字を
イメージスキャナやデジタルカメラで読み取り、コンピューターが利用できる文字コードに変換する技術です。
| 文字セット | 文字種 | 文字数 |
|---|---|---|
| JIS X 9010:1984 OCR-B基本 |
数字 | 10 |
| アルファベット(大文字、小文字) | 52 | |
| 記号等 | 31 | |
| その他 | 3 | |
| 合計 | 96 | |
| JIS X 9010:1984 OCR-B基本 OCR-K |
数字 | 10 |
| アルファベット(大文字、小文字) | 52 | |
| 記号等 | 31 | |
| その他 | 3 | |
| カタカナ等 | 63 | |
| 合計 | 159 | |
| JIS X 9006:1979 OCR-HN |
数字 | 10 |
| その他 | 1 | |
| 合計 | 11 |
バーコードは種類によって使用できる文字や文字の表現方法、桁数に違いがあります。
| 規格 | 文字セット | 文字種 |
|---|---|---|
| CODE39 | JIS X 0503 コード39基本仕様 |
数字 英語大文字 記号 |
| CODE128 | JIS X 0504 コード128基本仕様 |
数字 英語大文字 英語小文字 記号 |
| NW-7 | JIS X 0506 コーダバー(NW-7) |
数字 記号 |
| 郵政カスタマバーコード | 郵政カスタマバーコード基本仕様 | 記号 |
フォントには、全ての文字が一定の幅である固定幅(等幅)と1文字毎に文字幅が異なるプロポーショナルがあります。
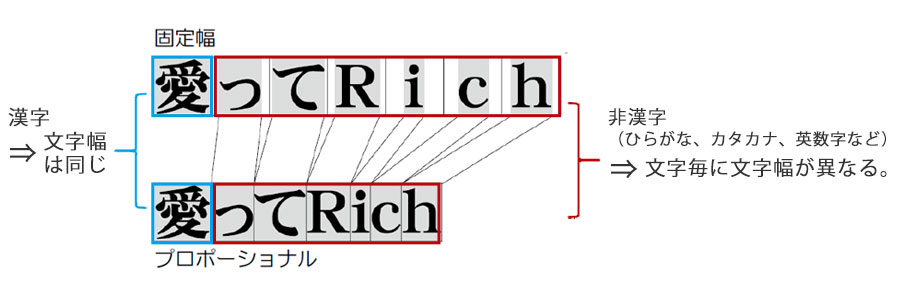
また、同じプロポーショナルでも書体によって文字幅は異なります。

日本語の文字セットについて、JIS X 0208(1978年に制定され、1983年、1990年、1997年に改訂)と
JIS X 0213(2000年に制定され、2004年に改訂)という規格が存在します。
JIS X 0208の1990年改訂版での例示字形をJIS90字形、JIS X 0213の2004年改訂版での例示字形をJIS2004字形と呼びます。
それぞれの規格で、一部の文字の字形が異なっています。
例 (左側がJIS90字形、右側がJIS2004字形)

様々な人にとって読みやすい、見やすい、読み間違えにくいなど工夫された書体をユニバーサルデザイン書体(UD書体)と呼びます。
当社におけるUD書体の方針
①「読みやすさ」
・文字の高さや幅を調整して、文章が自然に読めるようにする。
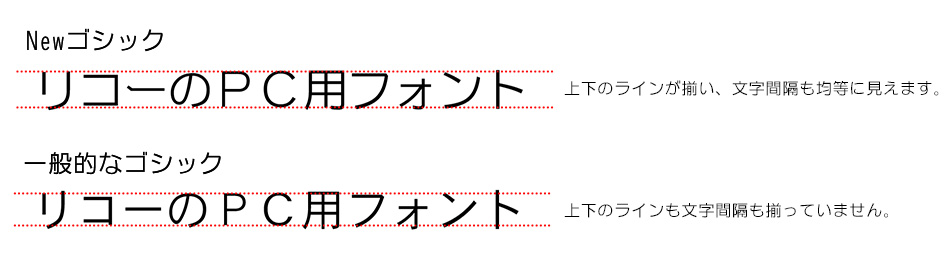
②「見やすさ」
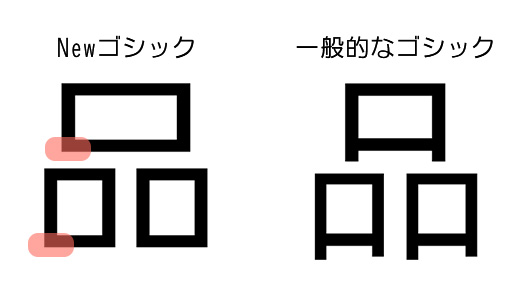
②-1:文字のふところ(文字の内側の空間)を大きくする。
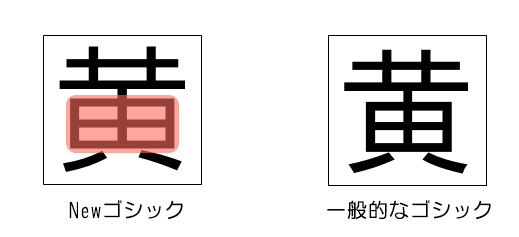
②-2:形状が似ている文字は違いを明確にする。
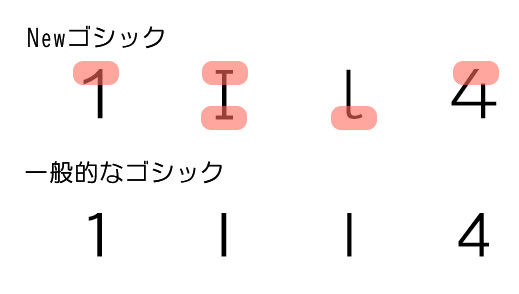
②-3:濁点や半濁点の区別を明確にする。

②-4:画数の多い文字は線の太さにメリハリをつける。
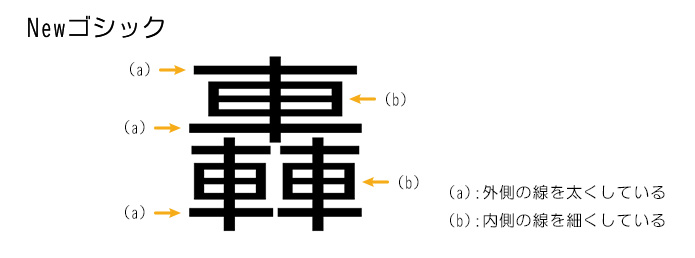
③「美しさ」
・装飾的な部分は削除してシンプルで美しくする。
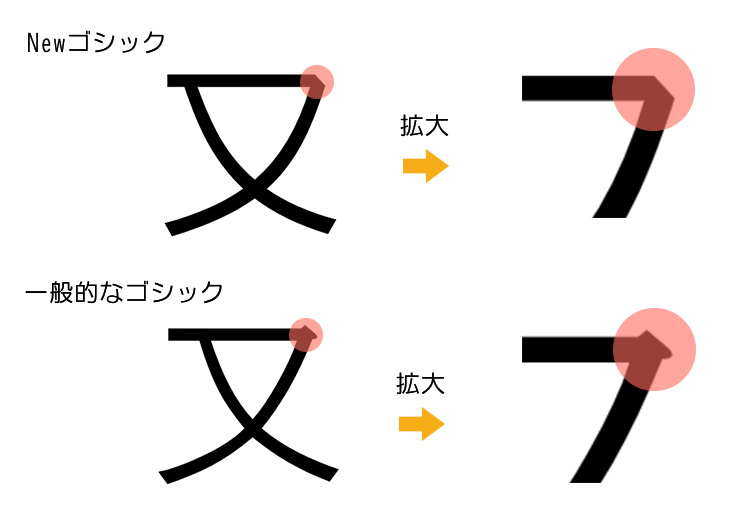
・曲げの部分は大きく柔らかな曲線で実現する。

外字とは、各種規格(UnicodeやJIS)に基づいた文字セットに含まれない文字のことを指します。
【どんな時に外字が必要か】
フォントを以下のように使用されたい方に外字の利用をおすすめ致します。
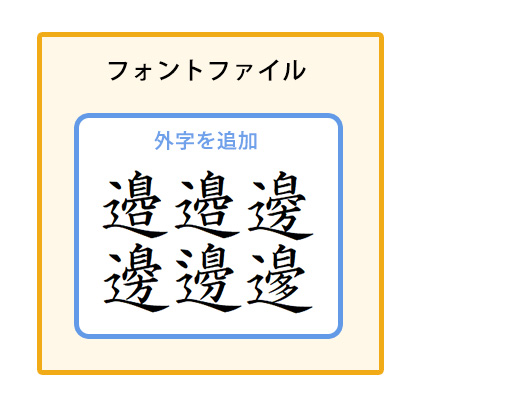
【外字を追加する仕組み】
フォントファイル内の外字領域に追加する
Unicodeの場合は、外字領域としてPUA(Private Use Area)が用意されています。
Windows®で使用するTrueType Fontの場合は、以下のようなやり方も可能です。
フォントファイルに外字ファイル(TTE形式)を関連付ける
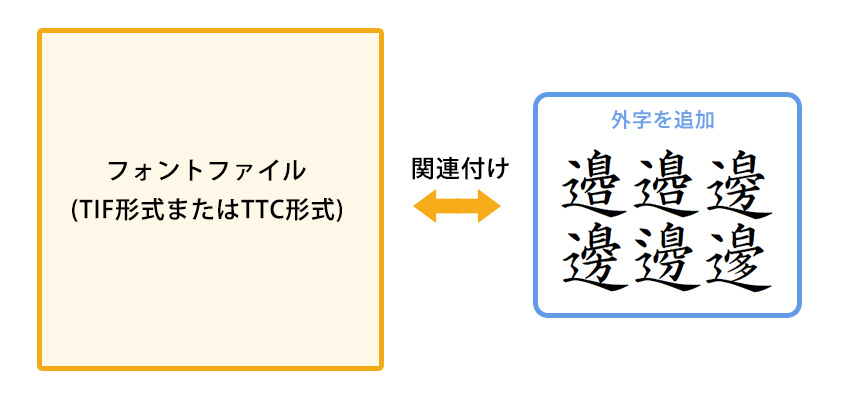
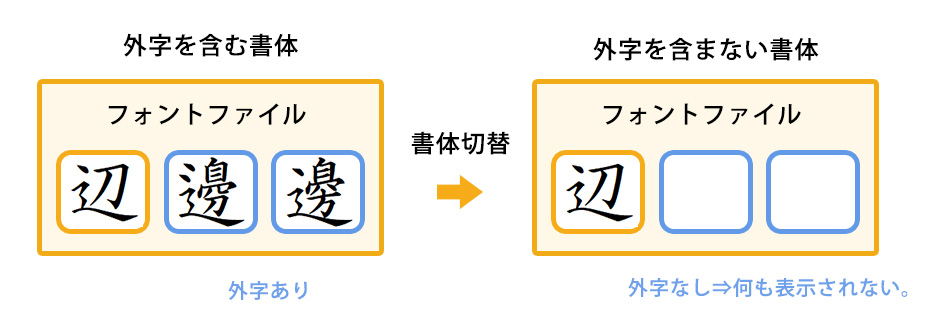
なお、外字は特定書体のフォントファイルに対して追加する為、別の書体に切り替えた場合、外字として追加した文字は表示されません。
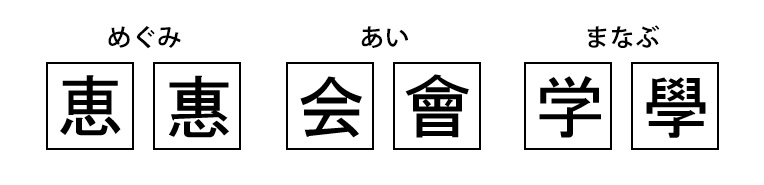
異体字とは、字の意味や発音・読み方は同じだが、字形が異なる文字のことを指します。
従来、異体字の表示には外字が利用されていましたが、近年は別の方法が確立されています。
フォントファイル(書体)の中には、複数の異体字に対して同じ文字コードが割り当てられているものがありますが、 この場合には同じ文字コードが割り当てられた異体字を使い分ける(=使いたい文字を指定して表示する)為の IVS(Ideographic Variation Sequence/Selector=異体字セレクター)という仕組みが必要となります。
IVSのイメージ
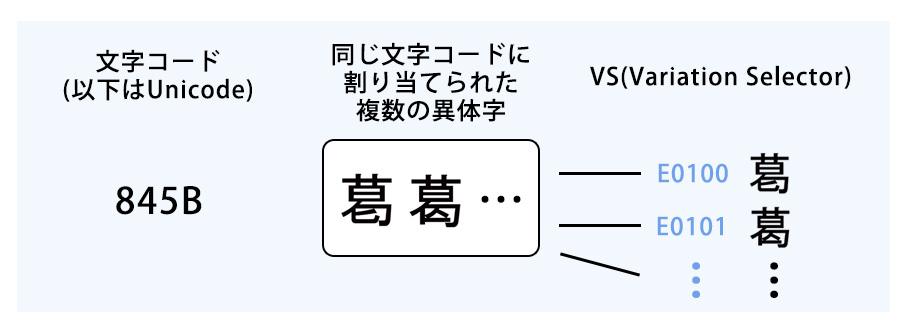
具体的には、文字コードの後ろにE0100、E0101など各々の字形を識別、特定する為の枝番号を付加することにより字形を区別します。
この枝番号のことをVS(Variation Selector=字形選択子)と呼びます。
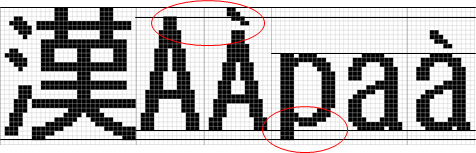
多言語対応をする場合、文字サイズのバランスを意識する必要があります。
日本語とのバランスを優先しなかった欧文
欧文らしい表示ができますが、言語を切り替えたときに文字サイズが大きく変わった印象を受ける恐れがあります。
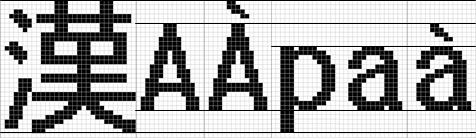
日本語とのバランスを優先した欧文
当社はこちらを採用しています。
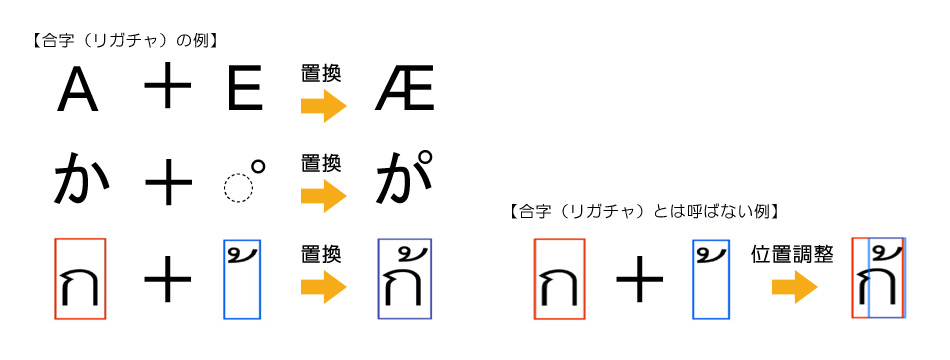
複数の文字を1つの文字に置き換えた文字のことを合字(リガチャ)と呼びます。
1つの文字に置き換えずに位置調整して表示した場合には合字(リガチャ)とは呼びません。
TrueType Font(及びRT Font)にビットマップフォントを内包することで対象のdot数ではビットマップフォントでの表示が優先され、文字潰れを防ぐことができます。
赤い文字がビットマップフォントです。
| ビットマップフォントを 内包している場合 | ビットマップフォントを 内包していない場合 | |
|---|---|---|
| 24dot |  | |
| 21dot |  | |
| 20dot |  |  |
| 18dot |  |  |
| 16dot |  |  |
| 14dot |  |  |
| 13dot |  |  |
| 12dot |  | 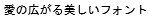 |
| 10dot |  |  |
| 8dot |  | 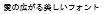 |
| 7dot |  | 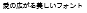 |